
Building JebBot: A Chess Clone
I've been playing chess since I was a little kid, and I would wake up early in the morning to play with my dad before he went to work. While it never became a competitive pursuit of mine, I would say I have a love and passion for the game and have continued to play regularly over my life. Playing chess might be the most consistent activity I partake in, and since I play online, I have found it rewarding to be able to look back over my progress as a player.
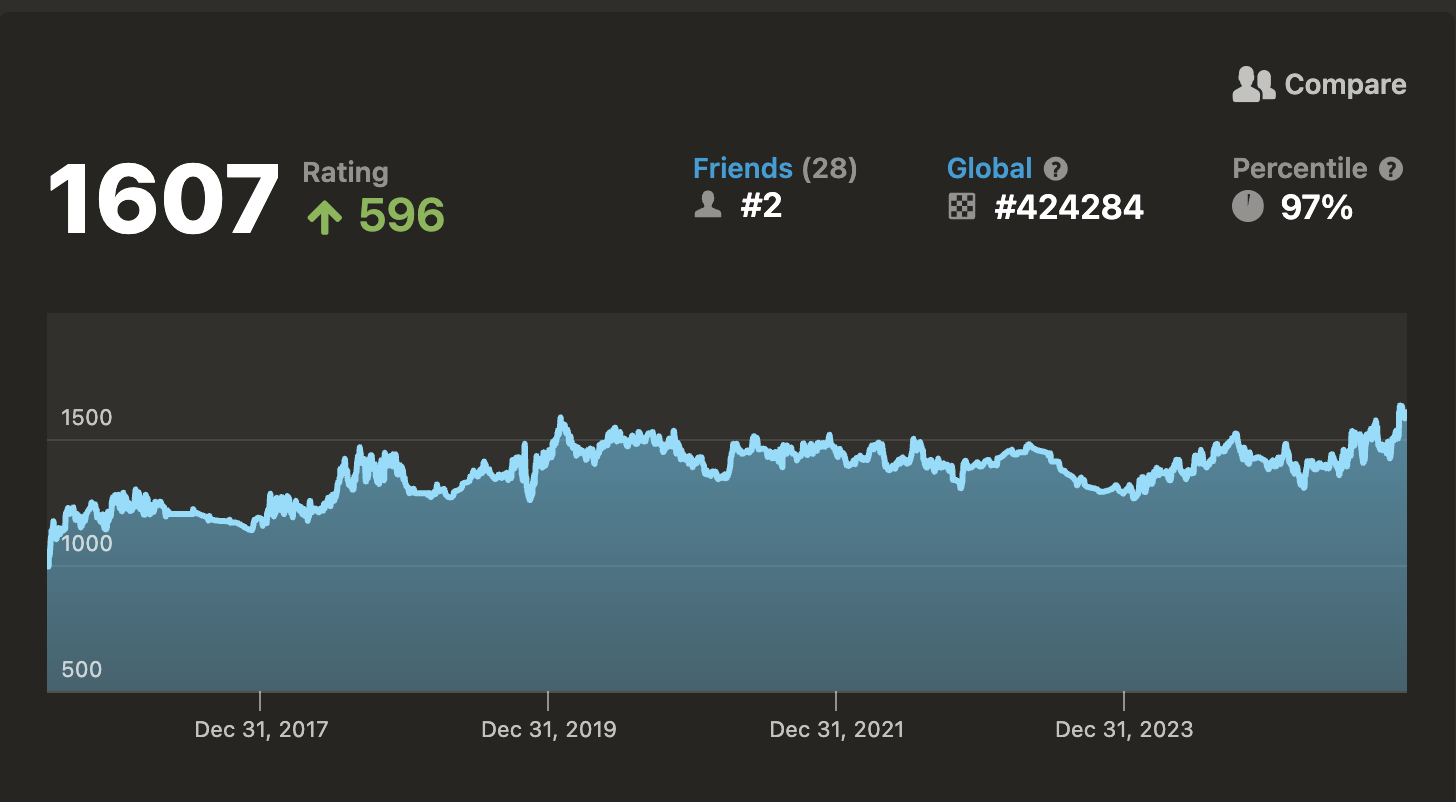
Beyond progress, my chess rating helps me look back and track moments in life. There is a big, flat section in 2017 -- while I was a camp counselor at Overland and looking for a full time role. Big gains as I worked at Google and played bughouse regularly with co-workers. Steep drops at the end of 2018 (moving cities) and early 2020 (covid).
This is all to say, in my chess there is a faint sprite of my life.
Everyone in tech right now seems obsessed with a) living forever and b)AI and maybe c) chess.
I thought instead of swapping my blood with a younger person or uploading my consciousness to live forever as a machine (so that I can interface with Ross Gellar), a chessbot would suffice. The idea of training a chessbot on my past game library so that it plays like me, and therefore, is some reflection of me is nice. And if I get hit by a truck tomorrow I think it would give my friends great solace to play against a poorly planned Danish gambit a few more times.
So for this project, I have a few goals:
- Build a digital chess-playing clone of myself
- Understand Neural Networks a bit better
- Push my use of AI coding
Here is how it went:
The Approach
I had to figure out how exactly I was going to get a chess model to play like me. It felt a bit complex and redundant to build a chess model from scratch (a la Alphazero) and just extracting insights from my games and hard coding rules in certain positions felt too rudimentary and wouldn't involve training a model.
So I went with -- in my humble opinion -- a pretty clever simple design. Instead of training a full chessbot how to play chess and instilling it with my style, I figured I could train a simple binary classifier. This classifier gets trained on a dataset that is half-my real moves and half- not my moves. As it trains it should get better at differentiating and therefore "learning" my style. The classifier after training can rate any position and move in terms of "does that look like a jeb move?".
How does that translate to a chessbot?
Using an existing chess engine set at my level (I'm using stockfish 1500) I can serve it 5 moves in every position. The style classifier then looks at each of the 5 moves and rates it as the most likely that I would play it. Higher confidence means the move is more like my style. Then we select the move with the highest "jebness" score. Repeat the process each position and we have a chessbot that is always picking the most jeb move. (This is the theory at least)
The Data Pipeline
I started by downloading ~8,000 of my games from Chess.com. Using claude, I wrote a simple client that pulls the games and stores it as JSON. I filtered out abandoned games, time-outs, and (this was a huge mistake) some of the opening moves. I then converted the remaining games into individual positions and moves. So each data example is -- 1) what does the board look like and 2) what move was made, which left 219,663 positions + moves. (filtering out my opponents moves was also maybe a mistake).
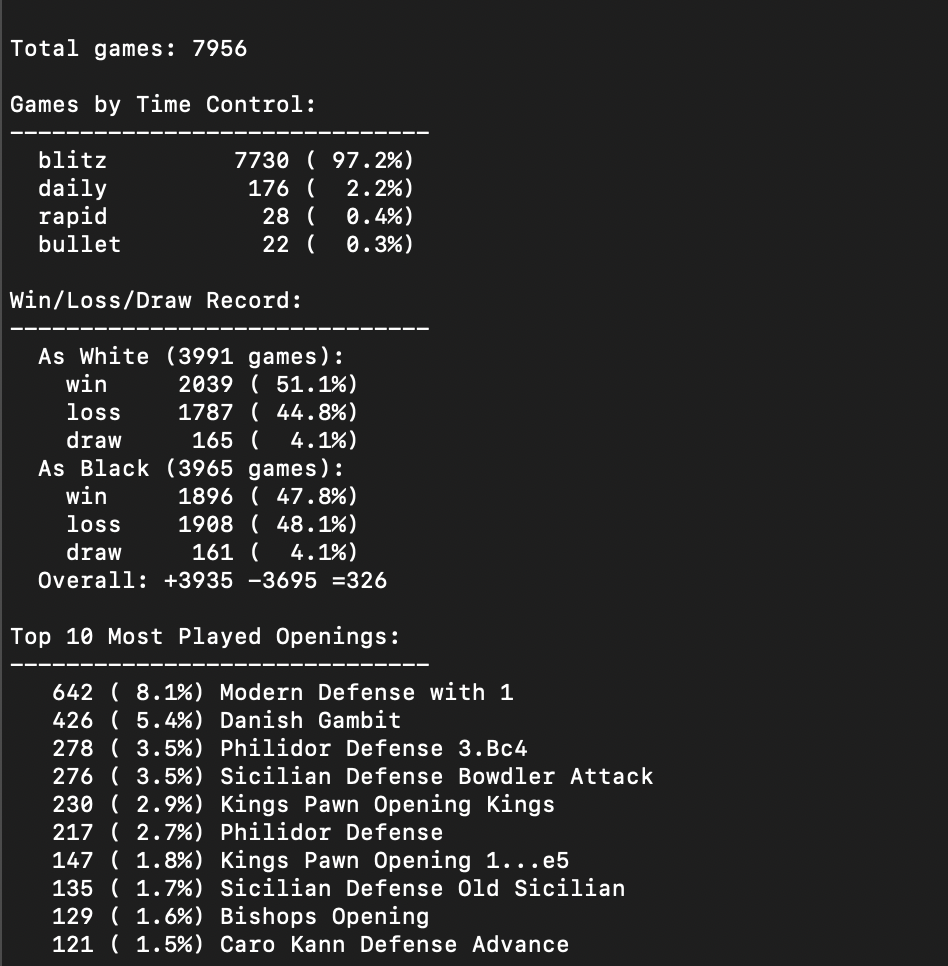
I needed to convert these positions into a 12x8x8 array: 12 channels (one for each piece type (p, k, q, n, b, r × 2 colors)) and a 8×8 board. Each channel is binary: 1 where that piece sits, 0 elsewhere. This is how we represent each "position". For each move: there are 64 squares a piece can move from and 64 squares it can move to. So we have an index of 4096 moves.
Now that we have a numerical representation of every position and move, we can start training.
The Model
The model is a binary classifier. Given a position and a candidate move, it outputs a probability: "Is this something Jeb would play?"
INPUT:
├── Position: 12×8×8 tensor (one channel per piece type)
└── Move: index 0-4095 → embedded to 64-dim vector
ARCHITECTURE:
├── 3 convolutional layers (12→64→128→128 channels)
├── Flatten to 8,192 features
├── Concatenate with 64-dim move embedding
├── 3 fully connected layers (8,256→256→64→1)
└── Sigmoid output (probability 0-1)
OUTPUT: "Is this a Jeb move?" (0.0 to 1.0)Once I had this architecture set I made a pretty dumb mistake. I tried to train the model which immediately started spamming 1 as the answer (aka these are all jeb moves). I remedied this with generated moves from each position from a 1500 stockfish.
Back to training:
- Positive: The move I actually played (target = 1.0)
- Negative: A move I didn't play (target = 0.0)
The Training Loop
- 80/10/10 split for train/validation/test
- Binary Cross-Entropy loss (standard for classification)
- Adam optimizer with learning rate 1e-4
- Early stopping with 10 epochs patience
- Dropout (0.3) to prevent overfitting – I added this after a few overfitting training runs.
I trained on a laptop using MPS acceleration.

I made this because I thought it would be fun to see the model actually make guesses. Every 100 batches, the trainer sends 6 random positions to a local web server that displays the board, the move, the model's confidence, and whether it was actually my move.
Results
After training, the model achieves ~60.5% accuracy distinguishing my moves from reasonable alternatives. I found this to be fine for the purposes of my own education and for being slightly more "me" than a neutral chess engine, so we are keeping on.
Some immediate improvements I could have made with training: more aggressive data cleanup, weight recent games higher, play with different dropouts and weight decay, and add a DPO step to give direct preference on if moves felt like me.
Brief aside – I pulled interesting examples out of the training run:
High-Confidence Correct (>90%): The model recognizes my signature moves. Aggressive queen. Danish Gambit continuation.
High-Confidence Wrong (>85%): Moves the model thinks I'd love, but I actually didn't play. The model has learned my patterns but overgeneralizes.
Missed Jeb Moves (<15%): Usually defensive moves.
Overall, it's a hard task for the model as there is often a "correct" best move in a position and even at 1500-1600, I should be finding that often. In those, there is no differentiation between a computer and me.
Playing Against JebBot
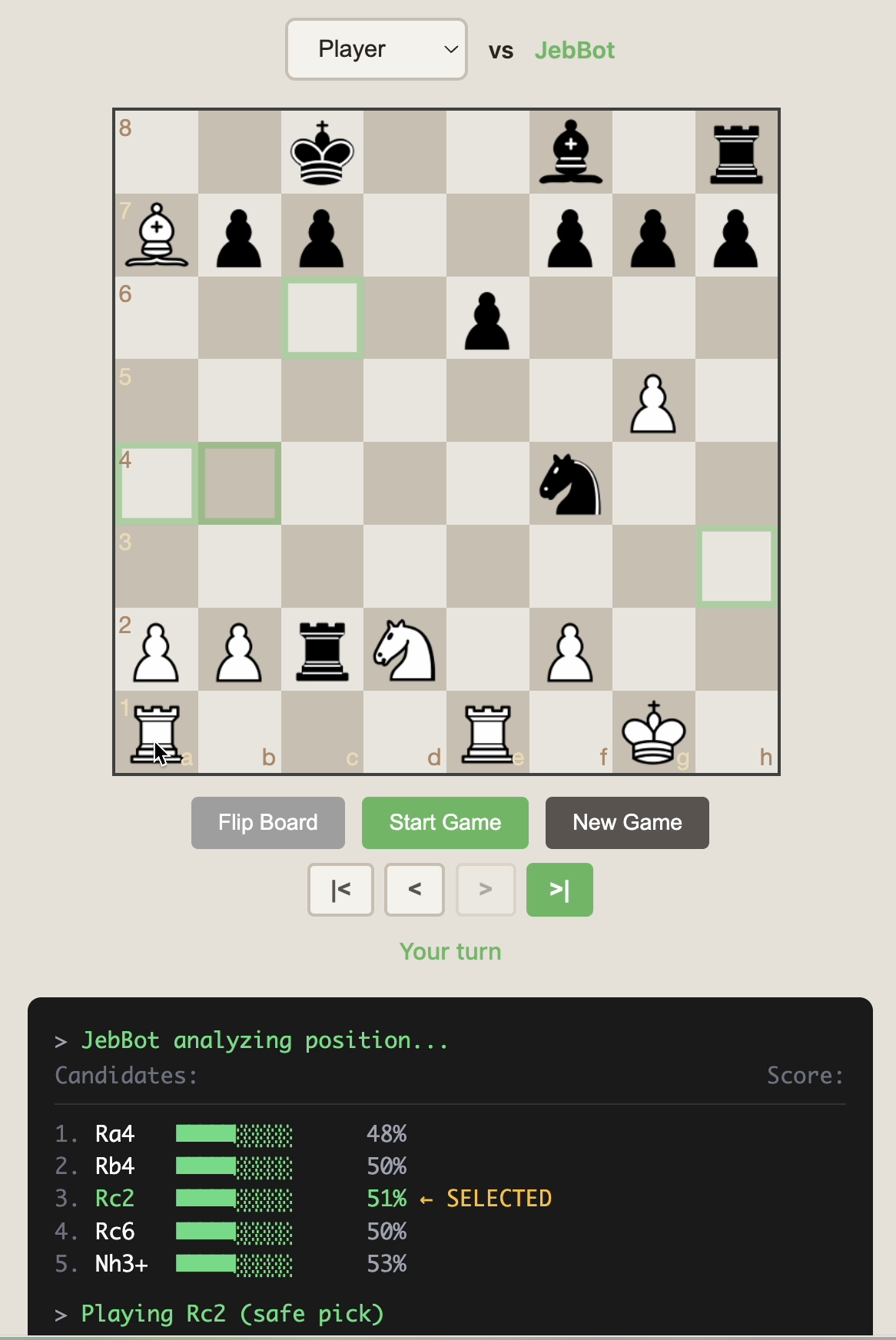 ƒ
ƒ The trained model doesn't play chess by itself—it scores moves. To actually play, I used claude to build an engine that combines: A stockfish 1500 model that serves moves + my classifiers. In initial playthrough, I found it passable with three major errors.
- Terrible at openings (remember I removed some opening moves from the dataset)
- Blundered too often (the stockfish data had no blunders, so I think it "learned" if I see a blunder it must be Jeb)
- Terrible at endgames (I think maybe just not enough data for those positions)
I made some adjustments to make it passable:
1. Opening Book (First ~5 Moves)
A weighted random book based on my actual opening preferences:
- As White: Danish Gambit 30%, Italian 30%, Other 10%
- As Black: 45% Caro-Kann, 45% Sicilian, 10% Scandinavian
2. Endgame Detection
When either side has ≤12 material points (roughly a rook or less), JebBot hands off to pure Stockfish.
3. Style-Quality Balancing
To fix the blunders, I just had to adjust how it picks moves:
- Find the "safe pick": first Stockfish move with >50% Jeb score
- If another move scores 15%+ higher, play that instead
- Fallback: if nothing is >50%, play highest Jeb score anyway
This balances two competing goals:
- Don't make moves so bad they're obviously wrong
- Let personality emerge when the choices are close
The Tech Stack
- Claude Code
- python-chess: Board representation and move validation
- stockfish: Candidate move generation and endgame play
- PyTorch: Neural network training
- wandb: Training logging and visualization
- Flask: Simple API server for the game UI
- chessboard.js: Interactive chess board in the browser
Everything runs locally.
What's Next
JebBot is functional but I'd like to host it on my website and possibly make my friends play the bot/me blind to see if I can beat them in a chessbot turing test.
To do so, I will likely have to continue to improve the selector model with DPO and the other training improvements discussed above.
Appendix
Model Size Breakdown
| Component | Parameters |
|---|---|
| Conv1 (12→64) | 6,976 |
| Conv2 (64→128) | 73,856 |
| Conv3 (128→128) | 147,584 |
| Move Embedding | 262,144 |
| FC1 (8256→256) | 2,113,792 |
| FC2 (256→64) | 16,448 |
| FC3 (64→1) | 65 |
| Total | ~2.6M |
Data Statistics
- Total games: 7,956
- Total positions: 219,663
- Dataset size (with negatives): 439,326 examples
- Training file: 48MB
- Trained model: 31MB
Training Configuration
- Epochs: 50 (with early stopping)
- Batch size: 64
- Learning rate: 1e-4
- Weight decay: 0.0001
- Dropout: 0.3
- Early stopping patience: 10 epochs
Repository Structure
jebbot/
├── jebbot/
│ ├── data/ # Download, parse, encode
│ ├── model/ # StyleSelector network
│ ├── play/ # Engine, openings, server
│ ├── training/ # Training utilities
│ └── visualization/ # Real-time training display
├── scripts/ # CLI entry points
└── data/
├── raw/ # Downloaded games
├── processed/ # Training positions
└── models/ # Trained checkpointsPartly inspired by Peter Whidden's "AI Learns Pokemon" video, but using supervised learning instead of reinforcement learning. Much simpler, faster, and suited for "behavioral cloning."